プログラミングを始めてから、比較的取り組みやすい「業務の自動化スクリプト」や「簡易Webアプリケーション」の開発は行ってきましたが、いつかチャレンジしたいと思っていたのが機械学習。
自動化スクリプトやWebアプリケーションはそれなりのものを作ることができたものの、機械学習モデル開発は2年ほど取り組んでいても精度が高いモデルが作れていませんでした。今回私が選んだ素材は「為替レート」ですが、ランダムウォークのパターンやノイズが多く、精度の高い予測を行うのが簡単ではありません。
試行錯誤に時間がかかってしまいましたが、一旦成果と言えるものが出たので、開発の経緯を書き残しておきます。特に、ランダム・ノイズ性の大きい対象を予測するためのヒントをお探しの方には、お役に立てるヒントがあるかと思います。
なお今回は、モデル開発の工程に絞っており、前処理にはあまり触れていません。ただそれは前処理や特徴量設定が重要ではないというわけではない点にはご注意を。
機械学習の予測対象は為替レート
機械学習で何の予測をさせたかったのかというと、為替レートです。
なぜ為替レートを選んだのかというと、以下のような理由があります。
- 公開情報でありデータ収集が容易
- ランダムウォーク成分とトレンド成分が混在しており、適度にチャレンジング
- MT4といったシステムトレードツールがあり精度検証がしやすい
- モデルの学習ノウハウを別の通貨ぺアにも横展開して検証しやすい
同じような要件なら予測対象は何でもよかったのですが、テクニカル分析などのノウハウも確立していることから、特徴量の設定・分析もしやすいのではと思い為替レートを選びました。
なお、予測方法は、「N分後の為替レートが 現在値+diff を上回るかどうか?」という二値分類問題(バイナリ分類問題)です。「将来の為替レートが何ポイントになるか?」という問題ではありません。二値分類の方がシンプルなモデルが開発できると考え選びました。
為替レートを予測することの難しさ
大学では金融工学も少しだけかじっていたので、それなりに精度の高いモデルをすぐに作れるだろうと考えていたのですが、全く甘い見通しでした。
為替レートは「数10年単位&1分おき」といった膨大なデータが手に入るので、学習するデータセットの量という点ではまず困りません。通常、機械学習においては、充分なデータセット量を確保することが難しかったりします。しかしその問題は簡単にクリアできました。
一方で難しかったのが、「値動きのアクションパターンが多すぎる」「非定常・レジームシフトによるランダムウォークの展開が多い」「経済イベントや市場の混乱といったノイズが多い」といったポイントです。つまり過去のアクションパターンを学習してもそのパターンが次回も繰り返されるとは限らず、意味のない学習を繰り返してしまうという。かといって深い学習をさせすぎると過学習になってしまう、ところが難しい点でした。
開発ですぐに思いつくアイデアは、「過去M分間の値動きやテクニカル分析などを特徴量として与え、将来N分後のアップ・ダウンを予測する」という手法ですが、全てのデータセットをフィルタリングしないまま与えてしまっても、予測精度50%(つまりランダムな予測)のモデルが出来上がってしまいます。これは、回帰やニューラルネットワーク・ディープラーニングを用いても同じです。
この時点で、私は特徴量の調整や、さまざまなアルゴリズムのテスト、またクラス不均衡の調整(将来アップ・ダウンするデータセット数を揃える)など、あらゆることを試しましたが精度向上につながることはありませんでした。
ランダムな為替レートを予測させる3つの開発テクニック
最終的に精度アップにつながったのは「局所的データセット」による学習でした。それに加えて、「バッファの活用」についても紹介します。
局所的データセットのフィルタリング
データセットがランダムななか、精度の高い予測をするにはどうすればよいか?結論は「局所性」でした。
つまり、「あらゆる場面で高い精度で予測する」ことを目指すのではなく、「他の場面では精度が悪くてもよいので、ある特定の場面では高い予測精度を発揮する」というモデルを開発すればよいということです。
実際に為替レートを眺めていると、「①レンジ相場でトレンド感がなく、次に上昇・下降どちらのトレンドに行くのかが全く予測できないランダムな場面」が多くあります。一方で「②明らかにトレンド感があり、力強く一定方向に動いている場面」もあります。①のような相場において将来のトレンドを予測することは困難ですが、②の場面に限ればそれなりの予測精度のモデルは作れるのではないかと思いました。
実際にこの方法は正解でした。やってみて実感したことは、為替レートのようなランダムな対象を予測するためには、「諦めるべきこと」「できそうなこと」の区別をしたうえで、「できそうなこと」に絞って学習をさせることの重要性です。
以下の「クラスター0」(青グラフ)は、相場全体(グレーグラフ)が上がっても下がっても一貫して下がっており、的確に下落トレンドを予測しています。
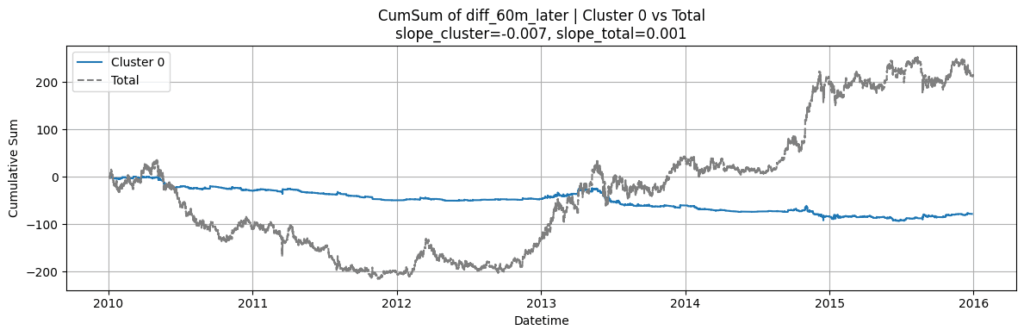
一方、以下の「クラスター1」は、相場と合わせて上下しており、的確に予測できていない可能性が高いです。
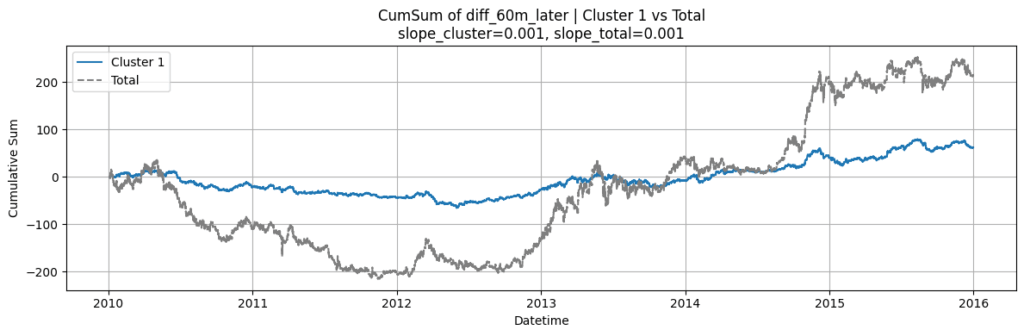
これは為替レートの値動きを見て気づいたところもありますし、その他に参考になったのは気象庁が出している論文で(どの論文かは失念)、いきなり遠い将来の天気を予測することは難しくても、直近の天気の予測は比較的しやすく、直近の天気の予測ができたらその次も順番に予測していく、という考え方がヒントになりました。
実際に開発においては、②のトレンド感がある場面をフィルタリングすることが次のステップになります。これにはさまざまな方法が考えられると思います。例えば、「SMA/MA」「DI+/DI-」「RSI」といったトレンド指標を用いて、ルールベースである一定の要件を満たしたデータセットのみを学習データとして与えるなどです。あるいは、ランダムウォークや高いボラティリティの局面を除外するために、「過去高値/安値」「SD」(標準偏差)などを用いて、比較的動きの少ない相場に絞るなどでもよいかもしれません。それすら面倒なら、特徴量をもとにクラスタリング分析をする、という方法もありだと思います。
いずれにせよ、好みや、難易度、工数、そして最終的な予測精度を考えながら、最適なフィルタリング方法を模索していきます。ちなみに私は全て試した結果、アンサンブル的な、つまりそれぞれのやり方を少しずつ取り入れたフィルタリング方法に落ち着きました。工数はかかってしまいましたが、これから取り組む場合、適切なフィルタリングができれば何でもありだと思います。
時間的バッファの活用
予測対象がランダム・ノイズ性の高いものの場合、フィルタリングしたデータセットでの学習が最も重要な学習テクニックといえますが、実用面を考えると、より安全な予測モデルを作りたいところです。そこで使えるのが時間的バッファです。
これは具体例を出したほうが話が早いのですが、為替レートを予測するにあたっては、30分後を予測するよりも1時間後の予測の方が難易度が高い傾向があります。つまり現在よりも時間的に離れているほど、予測の精度が下がってしまいます。
この問題を解決するには、「学習時においては1時間後の為替レートを予測させ、テスト・運用時においては30分後の為替レートの予測に活用する」という手があると思います。
レート的バッファの活用
時間的バッファと同じように、レートにおいてもバッファを活用できます。
例えば学習時には、「N分後の為替レートが+30を上回るか?」という観点で学習させ、テスト・運用時には「モデルが+30を上回ると予測した場合は、+15を上回る可能性が高いとみなす」とするやり方です。
このように、予測結果を保守的に活用することでより安全な運用が可能になります。
テクニックを活用した機械学習モデルの開発方法
ランダムウォークが多い為替レートの予測精度を高めるための重要な考え方は上でお伝えした通りなのですが、開発方法についても触れておきます。
データセット準備・前処理
為替レートはどこでもよいのですが、証券会社やMT4などでヒストリカルデータを入手しましょう。最低でも10年分のデータが欲しいところです。「1分ごと」「5分ごと」などなるべく細かく、「日時」「高値」「安値」「始値」「終値」が揃っていることが望ましいです。
次に、各レコードに、必要な特徴量を計算・格納していきます。
- 過去N分との差分
- 過去N分間のトレンド指標(MA、DI、RSIなど)
- 過去N分間のボラティリティ指標(ボリンジャーなど)
- 前後のイベント情報(外部APIなどで取得)
こういった前処理を行うにあたっては、Python/Pandasが便利です(というか必須?)。イベント情報の取得はハードルが高いのですが、使用しているAPIがあるならそれを使いましょう。
データセットのフィルタリング
ここまでで、各レコードに特徴量が格納されているデータセットが出来上がりました。次に、特徴量をもとにデータセットを分類します。分類方法は前述の通り以下のような方法があります。
- クラスタリング分析
- トレンド指標によるルールベースの分析
- ボラティリティ指標によるルールベースの分析
- 過去の値動きによるルールベースの分析
次に、その方法で分析したそれぞれのデータセットのクラスターを検証します。つまり、N分後の為替レートが目的変数なら、明らかに特定の傾向が見られるかを検証しましょう。
これは必須の工程です。クラスタリングの方法が優れているなら、この時点で予測しやすいパターンが現れているはずです。逆にどのクラスターもランダムウォークしているということは、後の工程でもうまくいかない可能性が高いでしょう。
優れたクラスタリングができているかどうか見極めるポイントとしては、「目的変数の独立性」が挙げられます。例えば、「将来の為替レートが上昇する傾向が高いクラスター」を探していて、「実際にあるクラスターの将来の為替レートの平均値が+30だった」という場合すぐに信頼できるでしょうか?仮に「該当の期間は相場全体が上昇トレンドだった」という可能性はないでしょうか?本当に優れたクラスターは、相場全体が上昇・下落トレンドどちらであっても、安定的に精度が高い予測をしているものです。
ここで、目的変数に一定の傾向が見られるクラスターを絞り込みます。今後はそのデータセットを活用することになります。
絞り込みデータセットでの学習
目的変数に一定の傾向が見られるデータセットを絞り込むことができたら、次はそのデータセットをもとに別のモデルで学習をさせます。
ここで「将来の為替レートが上昇している傾向があるクラスターを特定できるなら、クラスタリング分析をして、該当のクラスターを特定しさえすれば、後は何もする必要がないのでは?」という疑問も出そうですが、結論から言うとクラスタリングだけでは充分ではありません。なぜなら、クラスタリング分析はあくまでも特徴量のパターンによる分類であり、そのデータセットの中には、さらに「上昇するパターン」「下落するパターン」いずれも含まれており、それらを見極める必要があるためです。クラスタリングの目的は、あくまでも「局所性」の確立であり、ゴールは、「局所的な場面において精度が高いモデルを開発すること」になります。
とはいえクラスタリング分析ができていればその後の機械学習モデルの開発はシンプルです。「N分後の為替レートを予測する回帰問題」「N分後の為替レートが一定の値を上回る/下回るかどうかを予測する分類問題」いずれでもよいと思います。またロジスティック回帰、ニューラルネットワークなどもお好みで。
評価
機械学習の予測性能の評価はシンプルで、上昇を予測するモデルなら、特定の閾値を上回った場合の「正解率」(Accuracy)、「回数」(Support)、「目的変数の平均値」(Mean)が評価対象になるでしょう。
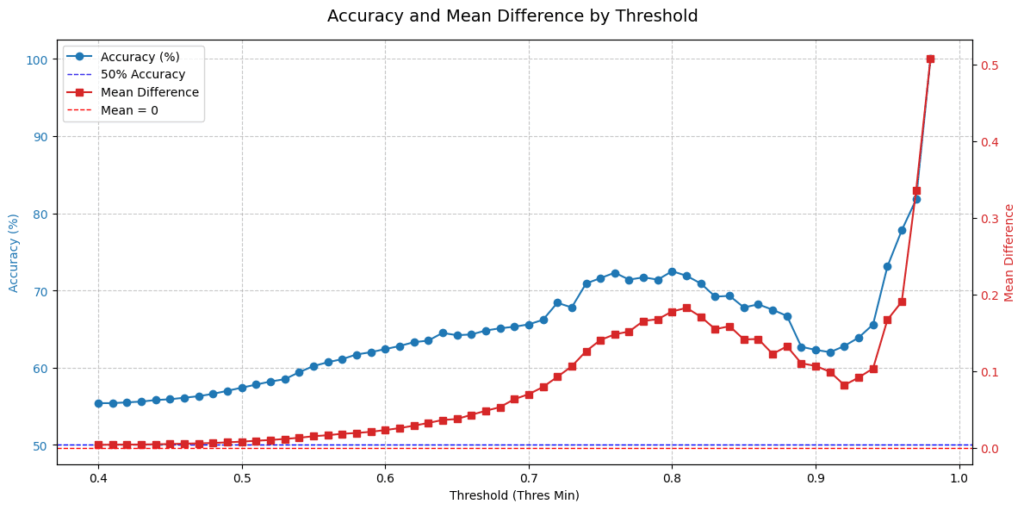
以下は、上昇トレンドを予測するモデルの評価結果です。青グラフは予測スコアが閾値を超えた場合の正解率で、赤はN分後の為替レートの平均値です。予測スコアが高い≒モデルが予測に自信を持っているほど、正解率が高く、かつ上昇幅も高いことが分かります。このモデルが0.0〜1.0の範囲で0.6を上回る予測をした場合、将来トレンドは上昇である可能性が高いと判断できます。
トレード実装
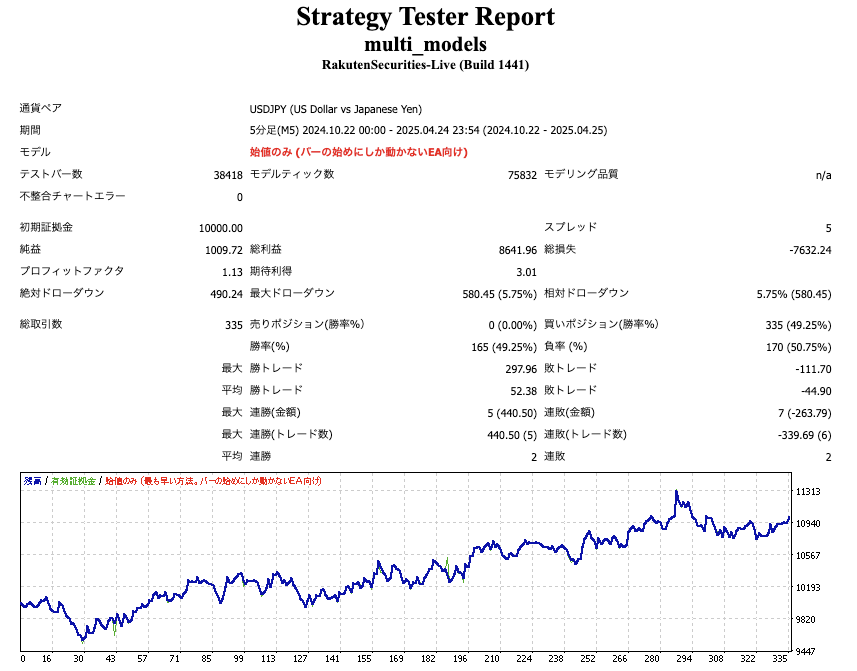
さらにトレードに応用するなら、「一定頻度で為替レートのデータを受け取って特徴量計算を行い、クラスタリング・二値分類予測を経て要件を満たした場合のみトレードする」というプログラムを組めば良いと思います。さらっと書きましたが、このあたりの実装は、MT4でやる場合、MQL側のスクリプト実装や、ローカルでのモデル予測用バックエンドアプリ開発もあり、それなりに手間はかかると思います。少なくともPythonによるWebアプリ開発(FastAPI、Flask、Djangoいずれか)ができる必要があるでしょう。
終わりに
機械学習のモデル開発でわかったことは、「ランダムな局面」「ノイズが多い局面」は予測するのが困難なので、「いかにランダム性やノイズを取り除いて、有利な土俵で戦うか」ということです。
私の場合は、為替レートのリアルデータの分析を熱心にせず、機械学習に頼りすぎてしまったことで、膨大な時間を浪費してしまいました。リアルデータにコミットしなければ見えないものがたくさんあり、逆に、しつこいくらいにリアルデータを分析すれば、簡単に正解にたどり着けることがあるようです。
機械学習の手始めとして、データを容易に集めやすく精度検証もしやすい為替レートを題材にしましたが、今後、面白い題材があれば取り組んでみたいと思います。
