
まずは、この悲劇的なスクリーンショットを見てください。
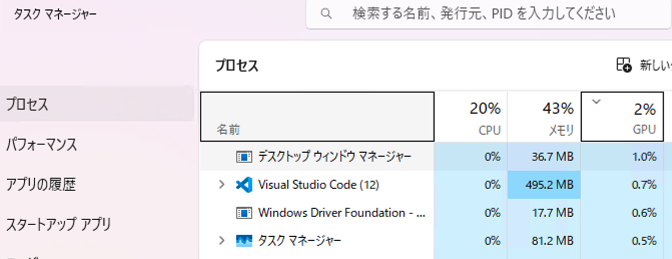
これは、私がWindowsで機械学習モデルを回している時のタスクマネージャーの様子です。左側でCPU(Python)が奮闘しており、ファンの音がジェットエンジンのように唸っています。一方で、右側をご覧ください。奮発して購入したRTX 5070さんは、稼働率2%。完全にお昼寝中です。
私は、この「モンスター」をただのディスプレイ出力機として使うために買ったのではありません。深層学習という名の終わりのない計算地獄を、少しでも早く終わらせるために大枚を叩いたはずです。
しかし、現実は非情です。最新のハードウェアを買えばすべてが解決する?いえ、そこには「グラフィックボードが新しすぎて機械学習ライブラリが対応していない」という、エンジニア特有の業(カルマ)が待っていました。
この記事では、WindowsユーザーがRTX 50XXシリーズ(Blackwellアーキテクチャ)でTensorFlowを動かそうとして絶望し、最終的に「NVIDIA公式Docker」という名の救命ボート(ただし重量級)に乗り込むまでの全記録を残します。
なお、定番のWSL(Windows Subsystem for Linux)ではGPU認識まではできたのですが、処理を開始するとメモリのダブル解放という得体の知れないエラーが出たので悪手と思われます。
なぜWindows環境×TensorFlow2.16×GPU(RTX5070)は失敗するのか?(不都合な真実と技術的背景)
そもそも、なぜ pip install tensorflow で万事解決しないのか。そこには、Google(TensorFlowチーム)とNVIDIA、そしてWindowsという3者の大人の事情が複雑に絡み合っています。
Windowsネイティブ版の死
まず、悲しいお知らせです。Googleは、TensorFlow 2.10を最後に、Windowsネイティブ版のGPUサポートを打ち切りました。 公式サイトには「WSL2を使ってね」とさらりと書いてありますが、要するに「Windows上で直接CUDAを動かす面倒は見きれないから、もうLinux(WSL2)でやってくれ」という通告です。
Compute Capability(計算能力)の壁
「じゃあWSL2を使えばいいんだろ?」と思い、Ubuntu 22.04で環境構築しても、RTX 5070の認識まではできたものの、起動するとメモリ関連のエラーで爆死しました。ここで立ちふさがるのが Compute Capability (CC) の壁です。
GPUには、ハードウェアの世代ごとに「バージョン」があります。
- RTX 30系 (Ampere):CC 8.6
- RTX 40系 (Ada Lovelace):CC 8.9
- RTX 50系 (Blackwell):CC 12.0 ← New!
TensorFlowの標準パッケージ(pipで入るやつ)は、ビルドされた時点で世の中に存在していたGPU向けに作られています。つまり、CC 12.0なんていう未知のオーパーツの言葉(命令セット)は理解できません。結果、CUDA_ERROR_INVALID_PTX という、「お前の言ってること分からん」エラーを吐いて死にます。
「置いてけぼり」の期間
NVIDIAはハードウェアを売りたいので最新GPUをどんどん出しますが、Google(TensorFlow)は安定性重視です。このスピード感の違いにより、最新グラボ発売から半年ほどは、「ハードはあるのにソフトがない」という真空地帯が生まれます。それどころかWindowsユーザーは見捨てられてしまっています。私は今、その谷底にいるのです。
救世主(仮)としての「NVIDIA NGC Docker」
標準のTensorFlowがダメならどうするか。答えは1つ。「ハードウェアを作った本人(NVIDIA)が配っている特製TensorFlowを使う」ことです。
彼らは自社の最新GPUを動かすために、独自にパッチを当て、最新のCUDAライブラリを詰め込んだDockerイメージを配布しています。それが NVIDIA NGC (NVIDIA GPU Cloud) カタログです。
| 比較項目 | 標準 TensorFlow (pip) | NVIDIA公式 Docker イメージ |
|---|---|---|
| 入手難易度 | 簡単 (pip install) | 面倒 (Docker環境構築が必要) |
| 最新GPU対応 | 遅い (数ヶ月〜年単位のラグ) | 爆速 (発売直後から対応) |
| 環境汚染 | ローカル環境が汚れる | コンテナ内で完結 (使い捨てできる) |
| サイズ | 数百MB〜数GB | 11GB超 (狂気) |
この解決策の最大のネックは、その巨大さです。「動く環境」を丸ごと配布するため、イメージサイズは10GBを超えます。しかし、背に腹は代えられません。ストレージの空き容量を捧げ、平穏を手に入れましょう。
NVIDIA NGC Dockerを導入・実行する手順(言われた通りにやれ)
ここからは、感情を捨てて作業を行いました。前提として、WindowsにDocker Desktopがインストールされているものとします。
手順1:NVIDIA NGC カタログからイメージを選ぶ
今回選ぶのは、Blackwellアーキテクチャに対応した最新版です。
- イメージ名:
nvcr.io/nvidia/tensorflow:25.02-tf2-py3
25.02 は2025年2月版という意味です。
手順2:勝利の呪文(docker run)を唱える
PowerShell、またはWSL2のターミナルを開き、以下のコマンドを叩き込みます。
# PowerShell
docker run --gpus all -it --rm ^
-v C:\Users\your_name\dev\project:/workspace/project ^
--ipc=host ^
nvcr.io/nvidia/tensorflow:25.02-tf2-py3 bash解説(という名の言い訳):
--gpus all:これがないとGPUが見えません。必須。-v ...:ホスト(Windows側)のソースコードを、コンテナの中(/workspace/project)に見せかけます。これをしないと、コンテナでコードを1から書く羽目になります。--ipc=host:【超重要】 これを忘れると、学習中にメモリ共有エラーで落ちます。「メモリはあるのに落ちる」という理不尽を味わいたくないので、黙って追加します。--rm:コンテナを終了したら自動で削除します。11GBのゴミを残さないためのマナーです。
手順3:11GBのダウンロードを虚無の心で待つ
コマンドを実行すると、以下のようなログが延々と流れます。
Unable to find image 'nvcr.io/nvidia/tensorflow:25.02-tf2-py3' locally
25.02-tf2-py3: Pulling from nvidia/tensorflow
...
(終わらない Pulling fs layer の列)コーヒーを淹れる時間は十分にあります。なんなら豆を買いに行っても間に合うかもしれません。これが「最新技術を使う」ための税金です。
ライブラリという注意点とトラブルシューティング(絶望への誘い)
無事にコンテナに入れたとしても、まだ油断はできません。
NVIDIAのイメージにはTensorFlowは入っていますが、pandas や scikit-learn 、matplotlib などの「データ分析三種の神器」が入っていないことがあります(バージョンによります)。コンテナ起動後、最初に行うのは結局 pip install です。
pip install pandas scikit-learn matplotlibGPUを酷使して爆速の世界
すべての苦労を乗り越え、コンテナ内でスクリプトを実行した瞬間、世界は変わります。
nvidia-smi コマンドを叩くと、そこには元気に稼働する RTX 5070 の姿が! そしてタスクマネージャーを見ると、ついにGPUの使用率が40%ほどに跳ね上がっています。
これまで1つのモデルに30分程度費やしていたのが、5分で終わるようになりました。ファンは轟音を上げていますが、それは悲鳴ではなく、仕事をこなしている歓喜の歌です。
まとめ
- Windowsネイティブ環境に期待してはいけない:開発者の時間は、環境構築ではなくコードを書くためにあるべきですが、WindowsでDeep Learningをする限り、その理想は捨ててください。
- 最新ハードウェアには「魔の空白期間」がある:発売日に買ったGPUは、機械学習においてはライブラリが追いつくまでただの高級な板になる可能性があります。
- Dockerは(デカいけど)裏切らない:NVIDIA公式イメージは、容量という代償と引き換えに、確実な動作を保証してくれます。
もしあなたが、新品のグラボを前にWindowsのTensorFlowで「なぜ動かないんだ」と頭を抱えているなら、迷わずDockerを入れてください。ストレージの10GBなんて、あなたの精神衛生に比べれば安いものです。さあ、不条理な設定ファイルとの格闘を終えて、モデルのトレーニングに戻りましょう。
