2024年3月、校正ツール「クエリズ」の本格バージョンを一般リリースしました。
もともとはSEO・記事制作の経験からぜひ欲しいと思ったツールで、約1年前にリリース・活用していた初期バージョンに大幅なアップデートを加え、多くの現場・場面・人に幅広く利用していただけるようになりました。
ツールの使い方は別のページで紹介していますが、ここでは開発面での仕様や技術メモを記します。
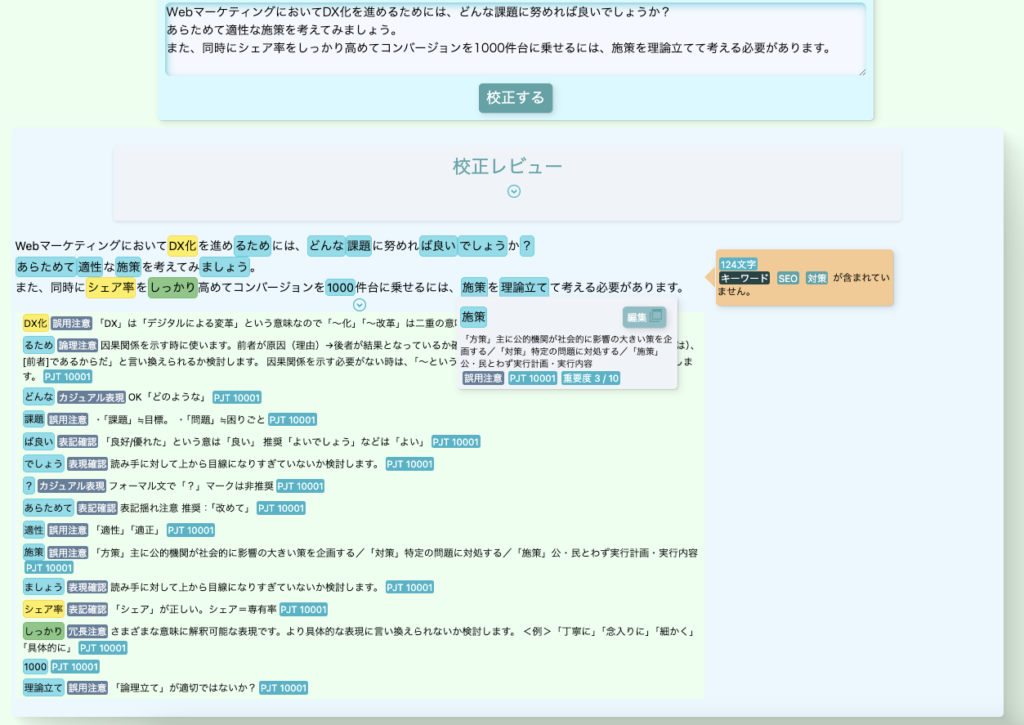
1.校正ツール「クエリズ」の概要
ツールの特徴
校正ツールを一言で表すとこちらです。
ユーザーが文章を入力すると、あらかじめデータベース(DB)に登録された校正ルールにもとづいてチェックを行い、ヒットする箇所をハイライト表示・コメント表示する。
より詳しくお伝えすると、以下のようなチェック機能がコアです。
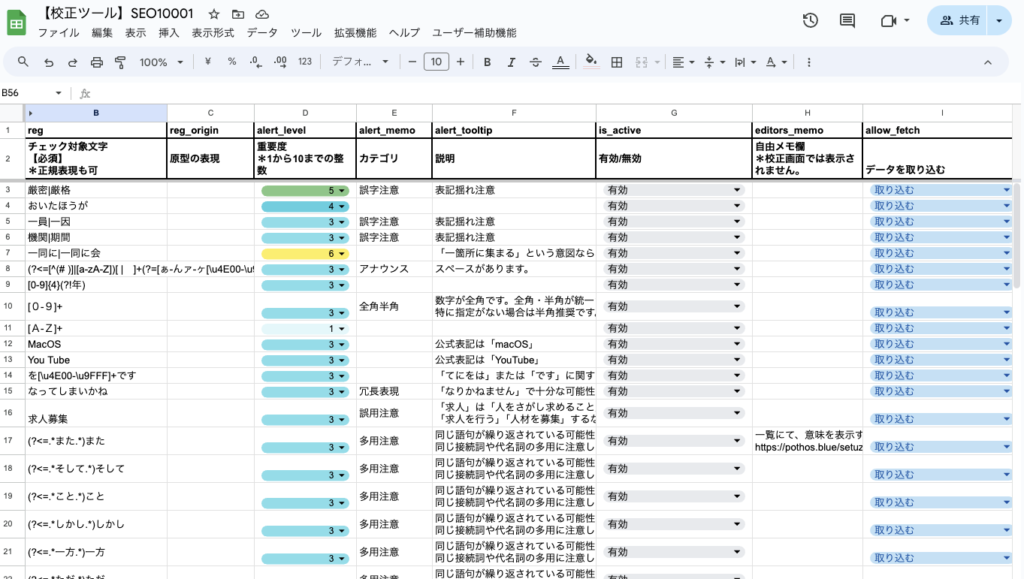
- 事前に定められた校正ルール(正規表現)に沿って正規表現チェックを実施して該当箇所をハイライトする
- 文字数やキーワードの含有有無といった各種チェックも行い結果をコメントで表示する
- 段落ごとに文章を分割し「見出し一覧」の表示や段落ごとのチェックも実行する
これだけを並べると真新しさがないようですが、後述するように、実際の現場で使えるよう「チームで育てていける柔軟性」「ルールのカスタマイズのしやすさ」を実現するための機能を多く盛り込んでいます。
開発の背景・ターゲットユーザー
ビジネス・プライベート問わず、文章制作・チェックをすることがある多くの人に役立つことを目指して作りました。
もともとのきっかけは、開発者である私自身がWeb記事の制作に長く携わっており、文章制作の現場で表記チェックやレギュレーションチェックに膨大な手間が発生するのに加えて漏れ・ミスが多発しやすく、それを解決したいと思い企画しました。既に他社さまが素晴らしい校正ツールを提供していたり、スプレッドシートの関数を使ってチェックする方法もあったりしますが、無料でかつ柔軟にカスタマイズして育てていけるツールが欲しく、これは自作するしかないと考えました。
ただ校正ツールを作るからには私だけでなく同じWeb記事制作プロジェクトに携わるディレクターさま、編集者さま、ライターさま、またクライアントさまにも役立てたく、さらにはWeb記事だけでなく幅広く文章制作・チェックに関係している人にも役立つものになればと思い、そのための機能も多く盛り込みました。
結果的に、記事制作だけでなく、個人的な書類の作成や、社内資料のチェック、メディアの校正・校閲、教育など多くの場面で役立つツールになっていると思います。
主な機能要件
基本的な機能は以下の通りです。
- 入力した文章の各種チェック
- 校正チェックにおける各種オプションの設定
- 校正ルールの新規作成・変更・削除
- Googleスプレッドシートからの校正ルールの読み取り
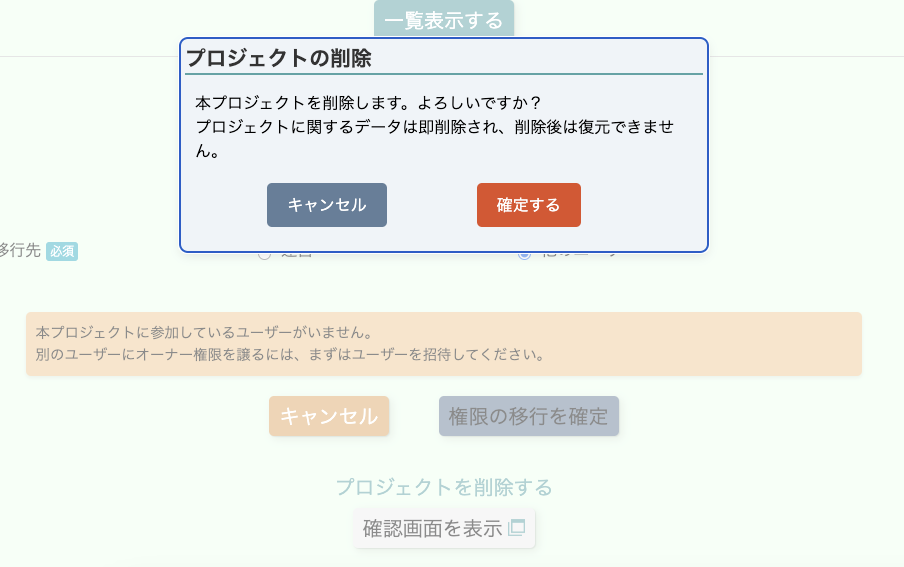
- 校正プロジェクトの新規作成・削除・移譲
- 校正プロジェクトの各種オプションの設定・変更
- 校正プロジェクトの招待・参加・参加者権限変更
- ユーザーアカウント登録・情報変更・退会
- サインイン/サインアウト
当初は個人用ツールでもよいかと考えミニマムな構成で、プロトタイプであるバージョン1は制作から3ヶ月ほどでリリースできました。その際はユーザーがフロント側からDBを操作できる機能はなかったため、開発の工数も抑えられました。
しかし、多くの人に使ってもらうシステムに進化させるとなると、校正ツール画面だけでなく設定画面の開発やDBと連携するバックエンドの実装も必要になるなど、膨大な設計事項の検討・機能が必要で、現行であるバージョン2の開発には4ヶ月ほどかかりました。
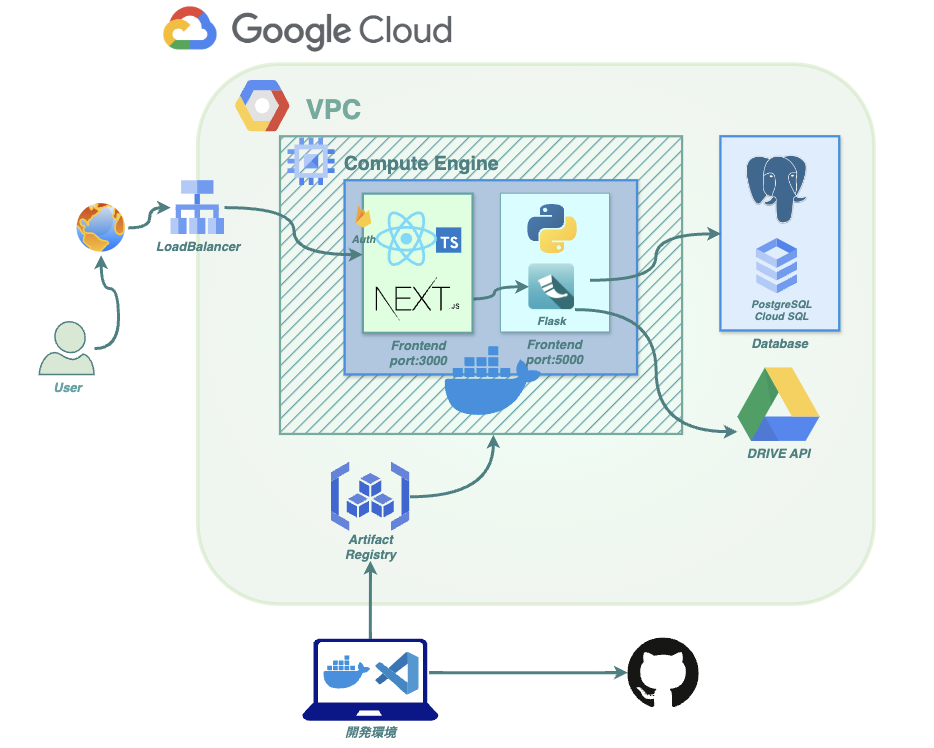
インフラ構成図
インフラ構成図は以下のようになっています。
AWSでなくGCPを選択している理由はいくつかありますが、以下が大きな理由でした。
- 「Vertex AI」など自然言語処理関連のAPIが豊富
- 「Google Drive API」をワンストップで使用可能
私の事業領域の1つに「SEO」もあり、SEOと言えば実質Googleがスタンダードで、加えてGCPにも関連技術が盛り込まれたサービスがあり、それが魅力でした。
また文章制作業務では「Googleドキュメント」や「Googleスプレッドシート」を用いることが多く、これを操作する「Google Drive API」をネイティブに使えるのも大きな理由でした。
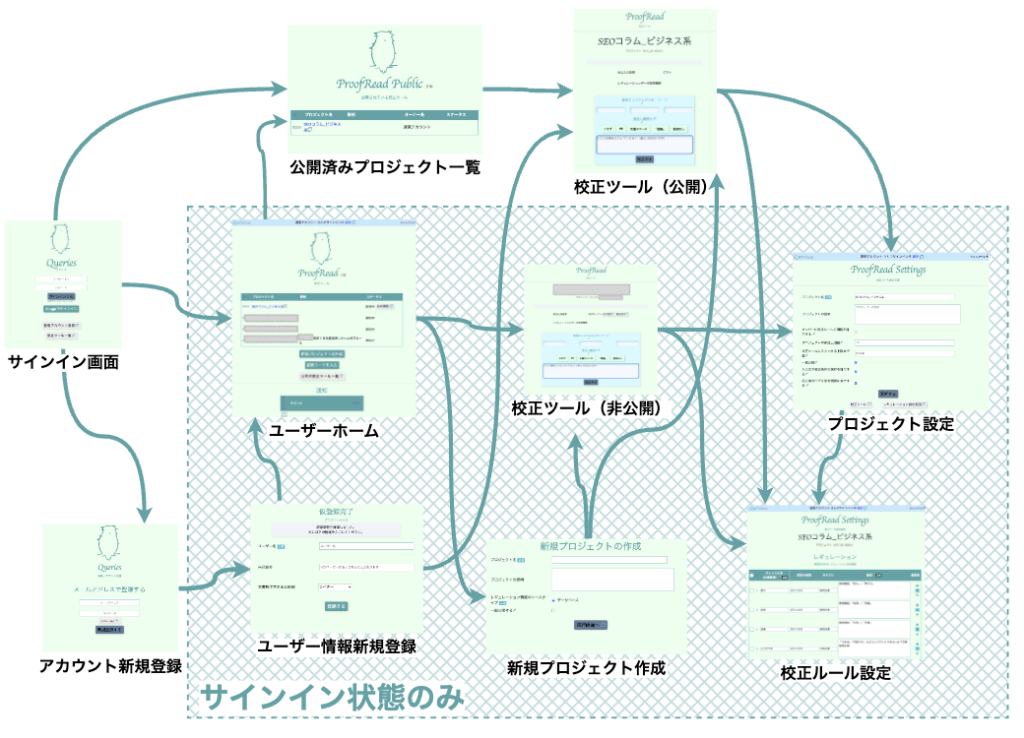
画面遷移図
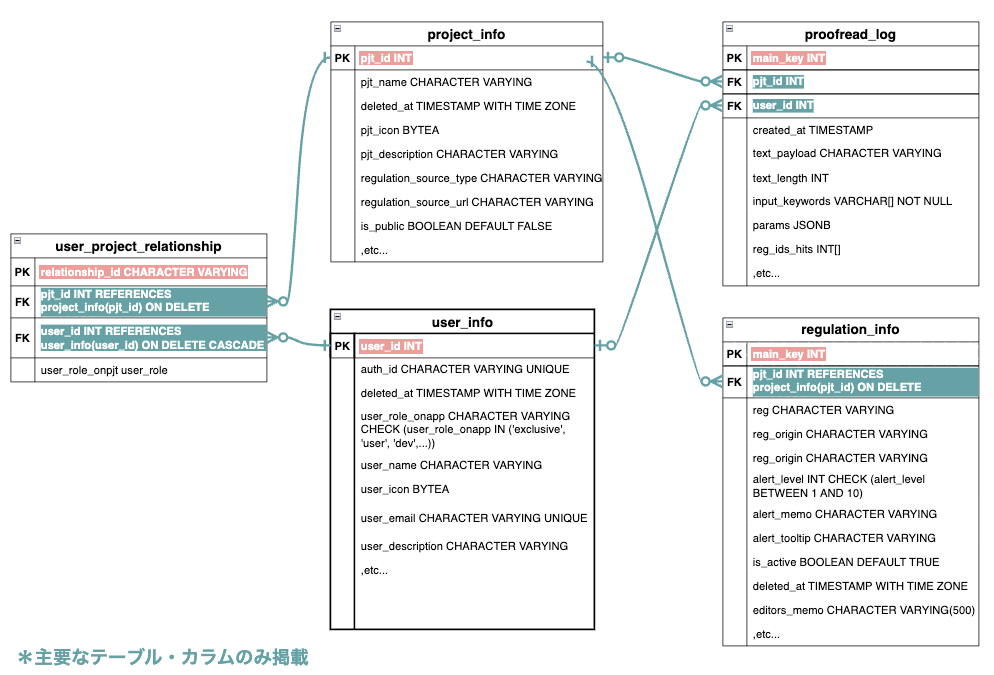
ER図
2.フロントエンドの技術仕様・考え方
プログラミング言語・フレームワーク
React+TypeScript/Next.jsを使用しています。
選定理由
もともとReact/Next.jsを選定した理由は特になく、当初の数ヶ月間伴走してくれたメンターさんに勧められるままでした。しかしこれが結果的に大正解。ReactにはuseStateやuseEffectといった非常に便利なフックス系モジュールが組み込まれているということと、公式・サードバーティのライブラリが豊富であること、さらにNext.jsがバックを支えていることで同じJavaScriptのままバックエンド処理もまとめて実装できるということで、開発を進めて知識がついていけばいくほど、その魅力を実感していきました。メンターさんには今でも感謝しきれません。
ライブラリ・モジュール
Reactには組み込み・サードパーティ問わずライブラリが豊富ということで、さまざま活用しました。
React系のライブラリ・モジュールで特に使ったものは以下の通りです。
- react-router-dom
- react-modal
- react-redux
- react-beautiful-dnd
- TypeScript
- memo
「react-modal」は、多くの人に使ってもらうことを念頭にすると、確認画面やポップアップ表示で確認事項・アナウンスを表示する必要があり、モーダルの形が最適だったため導入しました。なお各コンポーネントでモーダルを使うためにはContext APIを使用しています。
「react-redux」は、「ユーザー情報」のようにセッションを通して保持したい情報を格納するために使用し、ネットワーク・DBへの無用な負荷を抑えています。ページテンプレートが3〜4つになる段階で導入しました。なおモーダルといった機能系はContext APIを、storeデータの管理にはreact-reduxというように切り分けています。
「react-beautiful-dnd」はご存知の通りドラッグ&ドロップのライブラリですが、校正の次の機能として「記事制作支援機能」も開発中で、それに向けて導入しました。見出しの情報をユーザーが整理して記事の企画を練るような機能を想定しており、ここで活用します。なお通常の記事には「大見出し」「中見出し」「小見出し」のように階層が異なり、またある大見出しグループ内から、別の大見出しグループに子の見出しを移動したいケースもあります。ドラッグ&ドロップで実現するには入れ子構造でのデータの管理が必要となり非常に複雑で開発工数がかかっていますが、これが完成すれば半自動で記事制作できることになり、現場ではインパクトが大きいと思い期待しています(完成間近です)。
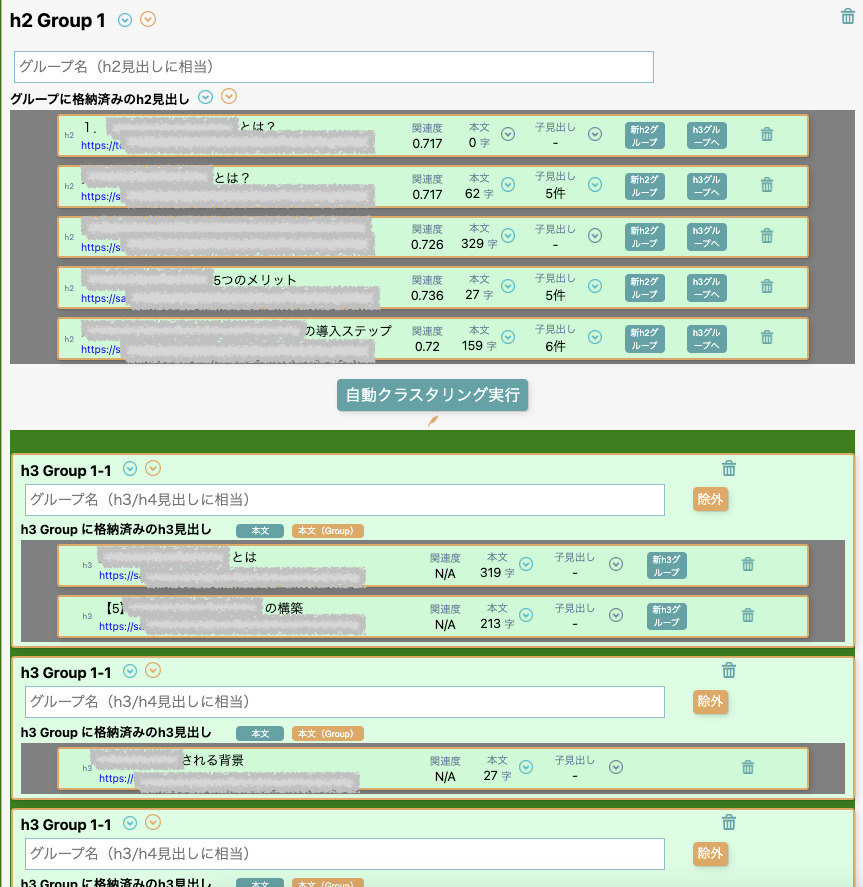
それぞれドラッグ&ドロップによる入れ替え可能です。
コード量がそれなりに増えてきた段階で「TypeScript」を導入しました。オブジェクト型変数のうちキー/値の数が多い・入れ子になっているような変数はメモとしてGoogleスプレッドシートなどで管理していましたが、校正ツールにもオプション機能を組み込んだり、Reduxのような状態保持ライブラリを導入したりすると、コンポーネント量が増えpropsの受け渡しも多発します。それに伴いGoogleスプレッドシートでの管理では更新漏れや更新の手間もあり無理が生じてきたのと、実際に開発時のバグも多く開発コストが増大していたのでTypeScriptの導入に踏み切りました。
その他、サードパーティ系のライブラリでは以下を使用しています。
- googleapis
- firebase(Auth)
「googleapis」は「Googleドキュメント」といった記事制作用リソースにアクセスするために、firebaseはサインイン認証のために利用しています。
フロントエンド開発での工夫
Reactと言えば「コンポーネント指向」ですが、TypeScriptということで「オブジェクト指向」によるクラスも大いに活用しました。
前提として、TypeScriptでtype/interfaceを定義するとそれだけでドキュメントになりますし、型エラーを排除できるので開発・保守効率を高めてくれるのは事実です。ただこれは「型」という観点では整合性チェックができるものの、「その値の範囲が不正か」(例:あるプロパティの値全てがtrueか?)のチェックまではできず、またクラスメソッドのように「あるクラス(またはインスタンス)と完全に紐づけられた関数」を定義しにくいという問題があります。
そこで、プロパティ数が多く、かつ頻繁に更新するような重要度の高いstateについては、独自のクラスを定義し、クラスインスタンスとして値を定義するようにしました。
class MainDataClass {
// クラスメンバ変数
…
// クラスメソッド
…
}
const [MainData , setMainData] = useState(
new MainDataClass());
…
setMainData((prev)=>{
//「不変性」原則の遵守が分かりやすくなるように2行に分けています
var newInstanceUpdated = MainData.updateData(key,value);
return newInstanceUpdated;
})こうすることで、stateの値を更新、取得する際に都度関数を記述する必要がなくなり、コードの効率性や保守性が非常に高まりました。もちろん、Reactの「不変性の原則」に沿って、各クラスメソッドではstateの値を直接変更しないように配慮しています。
このような書き方はオブジェクト指向の言語を扱うバックエンド側では当たり前のことですが、React.js/TypeScriptといったJavaScriptのフレームワーク・ライブラリで、このようなオブジェクト指向も取り入れている手法は検索しても見られませんでした。実際の現場ではどうなのでしょうか?
React+TypeScript+オブジェクト指向という欲張りな開発方法ですが、結果として見ればこの方法を取り入れたのは良い決断だったと思います。
3.バックエンド
バックエンドは、Next.js、Flask+FastAPI/Python、PostgreSQLを用いています。
選定理由
Next.jsは、Reactとのセットとして導入することになりました。ご存知のようにNext.jsではDB連携やAPI連携などの処理をJavaScriptでそのまま記述することも可能ではありますが、今回はそこまでは行わず、あくまでもフロントエンド(React)と、バックエンドのメインアプリケーションであるFlaskやFastAPI側との簡単な橋渡し役として活用しています。先述の通りメンターさんに勧められるままに導入したわけですが、かなりスマートで気に入っています。
次にFlask/Pythonです。これは主にDBやAPIへのアクセスを行うための中間エンドポイントとして使っています。DBやAPIへのアクセスだけであればRubyでも良かったのかもしれませんが、今後校正ツールや記事制作支援の機能拡充に向けて自然言語処理の技術をもっと取り入れたく、自然言語処理のライブラリが極めて充実しているPythonにしました。また、Pythonはもともと個人的に自然言語処理やデータ分析で使用したことがあり、選択の後押しになりました。
ライブラリ・モジュール
Next.jsで特に役立っているのは「API Routes」機能です。定番なので詳しい説明は割愛しますが、”/api?param=hoge”というようにReact側でfetchを行うと、Next.js(サーバーサイド)とリクエスト・レスポンスのやり取りが可能になる機能です。何が良かったかと言うと、「クライアントサイドからエンドポイントを秘匿しながらバックエンドにアクセスできる」という点です。また同じJavaScriptですのでReactの簡潔な記述を崩すこともありませんし、エンドポイントへのアクセスで発生しがちなCORSエラーも防げます。なおNext.jsではSSR(サーバーサイドレンダリング)も可能ですが、UIはかなり動的で、フロント・サーバーを分けると管理が煩雑になるため使用していません。ただNext.jsの活用方法はもっと追求したいと思っています。
Flask/Pythonでは、DBにアクセスしたりデータ処理したりするライブラリや、Google Drive APIにアクセスするためのモジュールを用いています。
- sqlalchemy
- pandas
- googleapiclient
現行のバージョン2ではまだFastAPI/Pythonを活用していませんが、いずれNext.jsアプリとは切り分けたスタンドアロン型として、自然言語処理系のプログラムを実行させるためのバックエンドアプリとして開発中です。「分かち書き」「形態素解析」「エンベディング」「クラスター分析・類似度計算」なども用いて、校正・記事制作に役立つ面白い機能をさまざま作っています。
- MeCab
- Gensim
- spaCy
- Transformer/Bert
- scikit-learn
バックエンド開発での工夫
FlaskアプリはDBへの接続を担う部分で、ただでさえSQL文は複雑になりやすいポイントでもあるので極力シンプルな記述を心がけ、またコードの再利用性よりも単一責任の原則を重視して、複数の処理を無理にまとめないことも徹底しました。結果的にエンドポイントの数は増えましたが、エラー発生時やメンテナンス時はスムーズなので現状これでよしとしています。
他に工夫したポイントは、リクエストのバリデーションです。以下のエンドポイント内ではリクエストのパラメータのバリデーションチェックにあえてクラスを定義しています。
@app.route('/getProjectInfo/',methods=['POST','OPTIONS'])
def get_project_info():
# 単一プロジェクト情報 + オーナー情報 + 関連情報を取得
# ユーザーIDは不要。純粋にプロジェクトIDのみ
# 引数 pjt_id,user_id(option)
if request.method == 'OPTIONS':
response = options_response()
return response
data = request.get_json()
class get_project_info_params_validation:
def __init__(self, data:dict):
self.pjt_id:int = int(data.get('pjt_id'))
self.user_id:int|None = int(data.get('user_id',None))
self.user_role_on_app:str = data.get('user_role_on_app')
print('get_project_info.data:', data)
try:
reqdata = get_project_info_params_validation(data)
except Exception as e:
print('get_project_info_params_validation_error:', e)
return fetch_response({'status': False, 'message': '必要なパラメータが含まれていません。'})
if reqdata.user_id != None and reqdata.user_id >0 :
query = text(
f'''SELECT * FROM projectinfo_owner_myrole
WHERE pjt_id = {reqdata.pjt_id}
AND my_id = {reqdata.user_id};''')
else:
query = text(
f'''SELECT *, 'guest' AS my_role_onpjt
FROM projectinfo_owner
WHERE pjt_id = {reqdata.pjt_id};''')
print('get_project_info.pjt_id:', reqdata.pjt_id, 'user_id:', reqdata.user_id)これはTypeScriptやフロントエンドでのオブジェクト指向の狙いと同じく、以下のようなメリットを期待しています。
- あえてクラスを定義することでコード自体がドキュメントになる
- エンドポイントにおいて必要なパラメータと期待する値が一目瞭然になる
- 不正なパラメータがあれば即時returnすることでその後の無駄な処理を防ぐ
- 即時returnの理由も返すことで開発者の保守性を高める
なお「関数の引数を指定して引数ごとにバリデーションを施す方法もあるのでは?」というご指摘もあるかと思いますが、それほど引数も多くないのでいったん1つのクラスでバリデーション・値参照する方法で開発の効率・保守性を比較してみたく、現状はこちらの方法を採用しています(その結果、パフォーマンスを見て変更する可能性もあります)。
全体を通して、「コードでなくドキュメント」というのを1つの開発テーマとして取り組みました。ややコード量は増えますが、エラーを防ぐだけでなく、未来の自分や、今後開発に参加してくれる方にも向けて可読性・保守性を高めるべくこのような書き方をしています。なお、FastAPIには「Pydantic」というライブラリがあり、リクエスト・レスポンスのパラメータの型を検証できるようです。こちらの導入も今後検討したいと思っています。
DBのテーブル設計についてもシンプルさを意識して、「1概念1テーブル」とし、テーブル連携は外部キーや中間テーブルを使う形としました。自慢できる工夫があるかと言うと微妙ですが、最低限、以下のようにTYPEを使って値の整合性確保を図ったり、関数を使って一部の変更が伝播するようにしたりなど、DBが矛盾のないような状態を効率的に保つための施策は施しました。
TYPE announcements_priority AS ENUM ('usual', 'important', 'must' ,'low')また「VIEW」も積極的に活用して、例えば「中間テーブルからあるユーザーが参加しているプロジェククトIDを取得→プロジェクトIDをもとにプロジェクトテーブルからプロジェクト名を取得」というようによくある処理をまとめることでエンドポイント側の負担軽減も考慮しました。
手元にある『達人に学ぶSQL徹底指南書』を改めて精読して改善したいです。
4.インフラ構築
GCPで構築しました。アプリ開発とは種類の違う面白さ、そして苦労がありました。
選定理由
GCPを選んだ理由は、冒頭でも触れた通り、以下の2点が大きいです。
- 「Vertex AI」など自然言語処理関連のAPIが豊富
- 「Google Drive API」をワンストップで使用可能
AWSとの比較で言うと、校正ツールがGoogle Driveと相性が良く、また自然言語処理系の技術はGoogleが先んじているので、ごく自然な選択でした。
特に「Google Drive API」「Google App Script」の公式ドキュメントは分かりやすいのでGoogleドキュメントやGoogleスプレッドシートに関する業務効率化のアイデア出しにも役立ちますし、またブラウザ上でAPIをテストできるのは大変助かります。
機械学習向けのプロダクトも充実しているのに加えて、「Gemini」など、文章校正・制作と親和性の高い技術が次々とリリースされており、楽しみな日々です。
活用プロダクト
- Google Compute Engine
- Could SQL for PostgreSQL
- Artifact Registry
- ネットワーク(VPC、DNS、ロードバランサ)
インフラについては「インフラ構成図」の通りです。
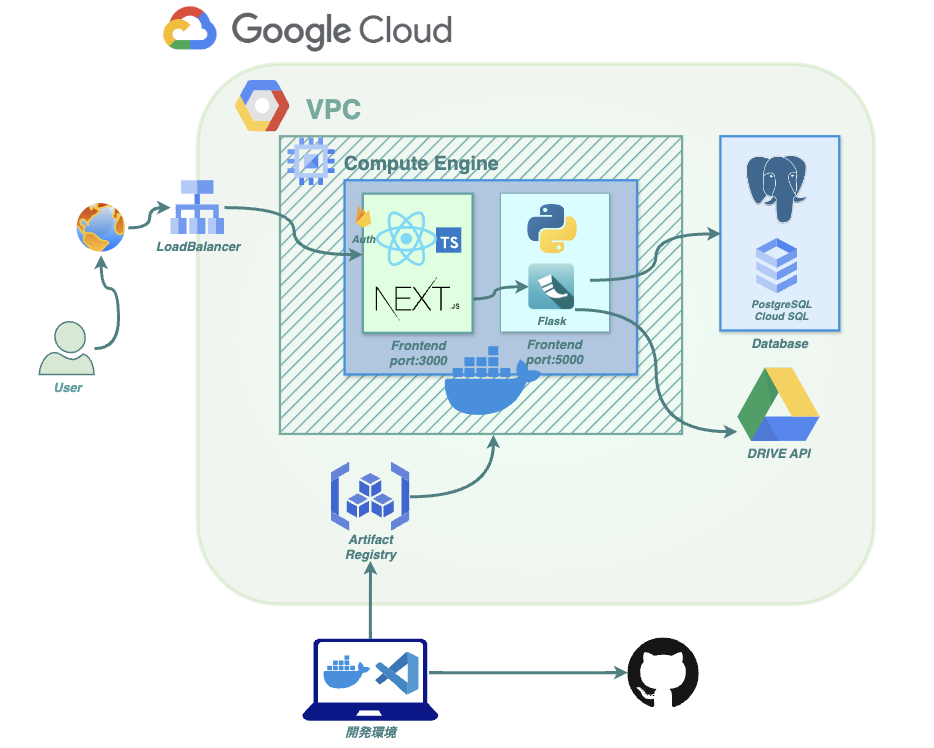
基本的にオーソドックスな形かと思います。GCPでVPCを構築し、Google Compute EngineにてVMインスタンスを構築。単一のドッカーコンテナ上で、メインのReact/Next.jsアプリとバックエンドのFlaskアプリを立ち上げています。
DBは利便性・バックアップの容易性からCould SQL for PostgreSQLを選択しました。
通常であればフロントのReact/Next.jsアプリとバックエンドのFlaskアプリは別々のコンテナで立ち上げてDocker Composeで連携させるところかと思いますし、今後はそのような形も選択肢の1つにしています。ただしコンテナを分けるとネットワークへの負荷、連携の手間が増えてしまうことが懸念で、また現状はFlask側で複雑・特別な書き方はしておらず、Next.jsとFlask側はそれなりに結びつきが強いという認識なので、今のところは同一コンテナという形にしています。
ただし、今後は自然言語処理に特化したバックエンドアプリも実装予定で、それはNext.jsと結合度は高くなく、個別に扱う方がメンテナンス性が高いため、別のVMインスタンスにてホスティングさせる予定です。
インフラ構築での工夫
ここは工夫というよりも苦労なのですが、初めてクラウドサービスを使う身としては、インフラ構築では戸惑うことだらけでした。
特に「権限」や「ネットワーク」は慣れない概念で、このあたりでハマることが多かったです。
権限については、「あるリソースが、別のリソースにアクセスする際は、自身のIDとスコープの許可が必要になる」ということを理解するまでに時間がかかりました。例えばVMインスタンス内で、Atrifact Registryからドッカーイメージをpullするような場合、同じVPC内であってもVMインスタンスのサービスアカウントにはAtrifact Registryの読み取り権限があらかじめ与えられている必要があります。他にも、アプリがGCP内のAPIを使用する際は、多くの場合、自身のIDを証明するための「サービスアカウントキー」と、適切な権限の付与、そしてAPIキーが必要になります。公式ドキュメントや参考サイトを何度も読み直してこれを理解できてからはハマることは減りましたが、一人で開発を進めていくうえでクラウドサービスを使いこなすのはなかなか難しいと実感しました。
ネットワークについても同様です。クラウドサービス内ではVPCやリージョン、ロードバランサなどの仕組みが、その他全体ではポート指定とSSL/非SSL通信の違い、またブログ用に用意するWordPress構築時のディレクトリ構造・wp-config.phpファイル・apachの設定などは勉強しながら進めていく、というやり方でした。
ひと通りこなした今となってはインフラ面の知識もある程度つき、公式ドキュメントやChatGPTに相談しながら構築できる自信はつきましたが、当初はやっとアプリがローカルのコンテナで動かせたと思っても、インフラ構築からデプロイ成功までの道のりが厳しく、フロントからインフラまでこなせるエンジニアの凄さを身をもって実感しました。
アプリ部分は何らか確信を持てる部分もありますが、インフラ部分は何とか動かせているというレベルという認識で、改善の余地はまだまだあります。
特にマシン構成の最適化やKubernetesによるオーケストレーション、ユーザー増に伴う負荷対策としてのスケーリングなど課題は山積です。GCPは極めて高度かつ複雑なサービスだというのは分かるのですが、10%も使いこなせていないと思います。できることならクラウドのプロの手を借りて設計を再考したいです。
5.開発での気づき
モノが出来上がっていく楽しさや自分・ユーザーの役に立つものができていく実感はありつつも、同時に未知・未熟さによる悪戦苦闘の連続でもありました。ただ曲がりなりにも一応の成果物をリリースできたということで、少なからず気づきも。ここにメモを書き残しておきます。
気づきは山ほどありますが、先輩エンジニアの方々が発信している内容と同じものも多くそれは割愛するとして、ここでは特に自分の言葉で書き残しておきたいものに絞ります。
コードでなくドキュメントを目指す
「コード」とはよく言ったもので、人間語と機械語の中間という概念が由来にあるのだと思いますが、その通り「暗号」であるとコードは素っ気なく冷たい存在になり、開発は迷宮に入り込んでしまいます。
開発において、記述したり読んだりするのはあくまでも人間であるので、コードは人間にとって暗号であってはならず、「ドキュメント」であるべきだと感じました。
例えば、変数・関数・プロパティの命名は端的に分かりやすくなければならず、また処理部分も初見の読解コストを極力減らすような工夫を施すべきだと。またコードを読む時の「分からない」「イライラ」という感覚に敏感になり、そのような感情があるということは改善の余地があるとコードが語りかけていると思うようにする、と。
当初の工数はかかる覚悟でTypeScriptの導入やオブジェクト指向のクラスの活用に踏み切ったのもそのような考えがあったからでしたが、結果的には開発の生産性が高くなり、また心理的にもコードに対して「確信感」「愛着」のようなものを持てるようになりました。
このあたりの考えでは、『リーダブルコード』や『良いコード/悪いコード』などが参考になりました。もしかすると、記事制作業務に携わってきた経験も活きているかもしれません(だと嬉しい)。
設計が先。コーディングは後
システム開発を進めるなかで、はやる気持ちとの付き合い方にも反省があります。
システム開発を「方針決め・設計」と「実装」に分けた場合、どうしても実装に目が行きがちで、目に見える成果、つまりコーディングが進んでいないと焦ってしまいます。特に日々発生している膨大な業務があり、それを自動化・効率化するようなツールを作ろうとしている場合はなおさらです。
しかし、まず手を動かすというやり方でコーディングに取り組んでも、その時は満足するようですが、後でそのコードを見てもコード全体との整合性確保やライブラリの活用、基幹コードの再利用方針などが練られておらず、結局リファクタリングになってしまうことがほとんどでした。
これは細かいコーディング部分でも同じで、複雑な分岐処理の場合、いきなり手を動かすと混乱しがちなのに対して、あらかじめフロー図を走り書きでもよいのでメモしておくと、それがいわばアンカーとなり、思考が分散せず着実にコーディングを進められることが分かりました。これはChatGPTやcopilotを使用する場合でも共通しており、頭のなかに確固とした方針があるうえで活用する分には有用ですが、曖昧な状態でコード案をアウトプットしてもらっても、自分の文脈では役に立たないどころか有害なコードが返ってくることがあるため、まず自分が方針・設計に確信を持ち、それに沿わないものは排除するという冷静な姿勢が役立つと思いました。
『ソフトウエア開発プロフェッショナル』の「愚者の金」セクションが参考になりました。
巨人の肩に立つ
せっかく先人がプログラミングの原則やノウハウを積み重ねてくれており、大抵の個人的な悩みは過去に誰かが同じようなことを経験して解決策も示してくれているので、それは積極的に使おうということです。
最初は参考サイトやChatGPTが適切なコードを端的に示してくれるのをよいことに喜んでコピーすることも多かったのは認めなければなりませんが、表層的な理解のまま使用した場合、後でそのコードは牙を剥いてきました。自分なりに試行錯誤を繰り返したところで、改めて「単一責任」「OCP」などの原則を見返すと、結局それらの原則の重要性に気が付いてリファクタリングする、ということがありました。
「早くリリースしたい」というはやる気持ちは抑え、回り道だと思っても誰かが記してくれた原則に立ち返って基礎基本を固めて方が高品質で開発効率も高いという当たり前のことに気がつきました。
トレードオフの優先順位を決める
「この機能があるとユーザーに嬉しいのは分かるが、実装コストはかかる。さて追加するか、捨てるか?」という場面は多くありました。
結論としては、「ユーザーの役に立つなら、よほどのコストがかからない限りは実装する」という選択をしてきました。
金融街を描いた映画で印象に残っているシーンがあります。際どいビジネスで儲けている投資銀行の社員が、会社を去った優秀なデータアナリストを高い報酬を掲げて呼び戻そうとする際、データアナリストはこう言いました。
「昔、橋を建設するプロジェクトに携わっていた。それまでは橋がないことで住民は川を迂回するために毎日1時間ほどかけて運転していた。それが、橋を架けることで移動は10分に短縮される。排出ガスの削減やガソリン代の節約にもつながる。橋の想定利用者は5,000人。1日あたり、50分×5,000人≒4,200時間の節約になる。年間なら約1,533,000時間。橋は最低でも50年は持つから……」
としたところで、投資銀行の社員は諦めたのでした。数字は不正確ですが、主旨はこのようなことを言っていました。
報酬は高いが、顧客の役に立たない商品を売りつけるビジネスへの皮肉でした。
この映画のシーンとツール開発では文脈は異なるようですが、「ツールにその機能を追加することで利用者の時間・労力の節約や品質改善に役立つなら、ある程度開発コストがかかっても実装すべき」と考えています。
その結果リリース時期は伸びましたが、それなりに役に立つものができたのではないかと思っています。
6.校正ツール「クエリズ」の今後
校正ツールとして、とにかく多くの方に使っていただければと思っています。
そもそもこのツールを開発したのは、記事制作に携わる私自身が、実際の現場で「文章の品質チェックが大変」「レギュレーション・表記漏れがある」「SEO的に改善の余地がある」「複数のクリエイター間にてレギュレーション・表記ルールの統一が大変」といった問題を感じ、解決できるようなツールを熱望していたからでした。そして前身である簡易版のバージョン1を開発し使ってみて、その効果を確信しました。
そしてこのツールは、私と同じように記事制作に携わる方はもちろん、メディア運営や社内文章制作、教育などさまざまな場面でも活用できると思います。他にも校正ツールはありますし、スプレッドシートの関数を使ってチェックする方法もありますが、「クエリズ」は基本機能は無料かつ、スプレッドシートよりも柔軟かつ直感的に使える設計になっています。
今回のバージョン2へのアップデートで、多くの方がさまざまな用途で使えるようになりました。複数の人が関わる制作現場でも使えるよう、「公開/非公開設定」や「メンバーの招待・権限設定」といった便利機能も数多く盛り込んでいます。
自分でも使っていきますし、多くの人に使っていただけるとありがたいです。また要望やフィードバックにはできる限りお応えしていきたいと思っています。
また、現在は校正の方法はシンプルに正規表現に基づくルールベースですが、自然言語処理を使ってやりたいこともたくさんあります。このあたりは実装の段階で追って公開できればと思っています。なお生成AIの活用も検討してきましたが、試行錯誤してみたところレスポンスにはブレがありコントロールが困難で、記事の品質担保ためのツールで活用するには不安な要素の方が現在は大きく、今後に期待というところです。
さらに、現在は「クエリズ」は校正ツールがコアですが、まだまだ追加したい機能・ツールはあります。
- Googleドキュメント・スプレッドシートの校正機能
- Webサイトの記事の一括校正機能
- 記事制作支援ツール
- WebサイトのSEO・コンバージョン分析機能
いずれも記事制作や、SEO支援に携わってきたなかで「欲しい」あるいは「あれば多くの人に役立つ」と確信したものです。いずれも構想はありますが、まだ卵から孵るばかりの雛の状態。お役に立てるように開発を進めていきます。
7.エンジニアとしての今後
噂によると、エンジニア業界は人手不足だと聞いています。
もしお役に立てることがあればお力になりたいと思っています。
ご連絡いただく際はこちらからどうぞ。